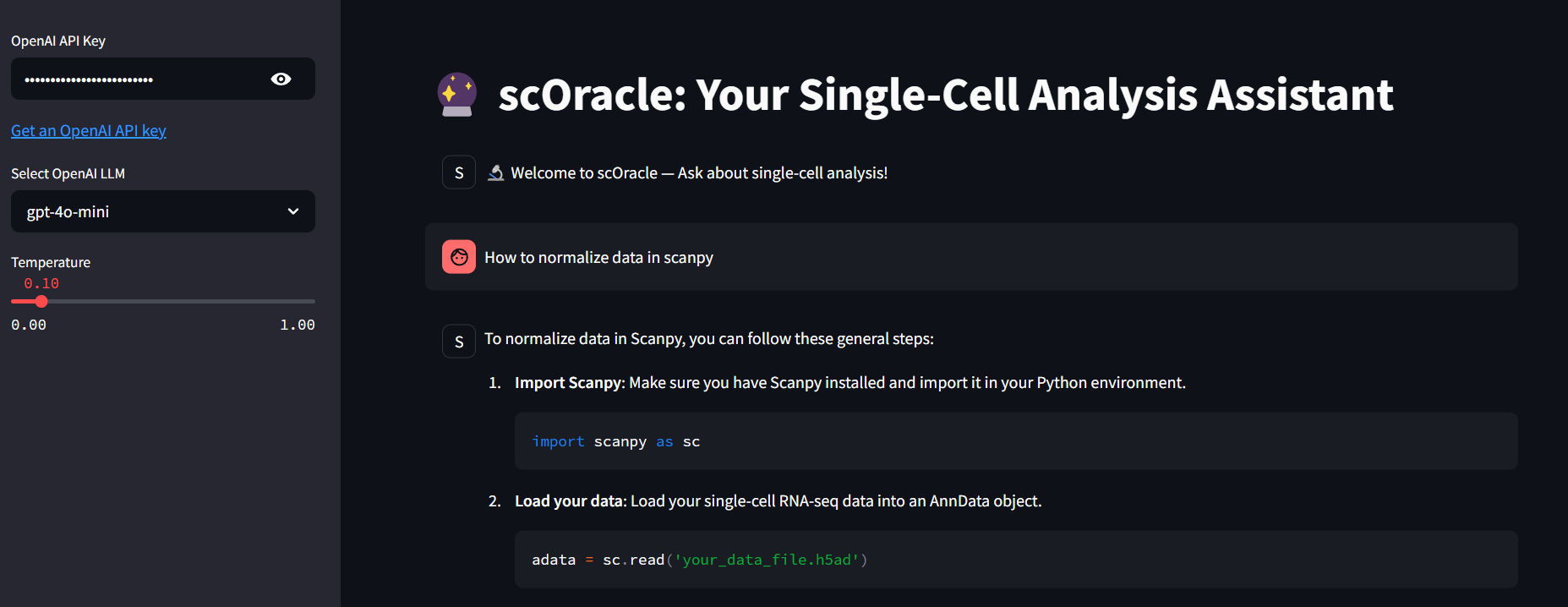
Building a RAG-Powered AI Chatbot for Single-Cell Analysis - Part 4: Streamlit UI
Published:
In this post, I will transform the comand-line version of scOracle into a fully interactive chatbot by creating a clean, browser-based interface using Streamlit.
Initializing Streamlit Page
import asyncio
import chromadb
import os
import openai
import streamlit as st
from llama_index.core import Settings, VectorStoreIndex
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.llms.openai import OpenAI
# === CONFIGURATION ===
CHROMA_PATH = "../chroma_db"
COLLECTION_NAME = "scoracle_index"
TOP_K = 8
Settings.embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L6-v2")
# === Streamlit UI Setup ===
st.set_page_config(page_title="scOracle", page_icon="🔮", layout="wide")
st.title("🔮 scOracle: Your Single-Cell Analysis Assistant")
# === Initialize session state for chat history ===
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = [
{"role": "scOracle", "content": "🔬 Welcome to scOracle — Ask about single-cell analysis!"}
]
Sidebar for entering OpenAI API key and LLM configuration
# === Sidebar for OpenAI API Key and LLM parameters ===
with st.sidebar:
# API key
openai_api_key = st.text_input(
"OpenAI API Key", key="openai_api_key", type="password"
)
"[Get an OpenAI API key](https://platform.openai.com/account/api-keys)"
# LLM model selection
openai_model = st.selectbox(
"Select OpenAI LLM",
options=["gpt-4o-mini", "gpt-4o", 'gpt-4.1-nano'],
index=0,
)
# LLM model temperature
temperature = st.slider(
"Temperature", min_value=0.0, max_value=1.0, value=0.1, step=0.1,
)
if "last_model" in st.session_state and (
openai_model != st.session_state.last_model or temperature != st.session_state.last_temperature
):
st.warning("⚠️ Changing model or temperature will reset scOracle's chat history.")
st.session_state.last_model = openai_model
st.session_state.last_temperature = temperature
# === Require API Key ===
if not openai_api_key:
st.warning("Please enter your OpenAI API key in the sidebar to begin.")
st.stop()
openai.api_key = openai_api_key
Loading the knowledge base and set up chat engine
I used the @st.cache_resource decorator to prevent Streamlit from reloading the Chroma vector database on every interaction. This ensures the vector store, index, and LLM setup are only initialized once per session.
# === Retrieve the Chroma vector store, set up LLM and chat engine ===
@st.cache_resource(show_spinner=False)
def load_index_and_engine(model, temperature, api_key):
"""Load the Chroma vector store"""
chroma_client = chromadb.PersistentClient(path=CHROMA_PATH)
collection = chroma_client.get_or_create_collection(COLLECTION_NAME)
vector_store = ChromaVectorStore(chroma_collection=collection)
index = VectorStoreIndex.from_vector_store(vector_store)
llm = OpenAI(
model=model,
temperature=temperature,
system_prompt="""
You are scOracle, a scientific assistant for single-cell RNA-seq analysis.
You can answer technical questions using your knowledge of documentation, code, and tutorials from bioinformatics tools such as Scanpy.
"""
)
print(f"Using OpenAI model: {model} with temperature: {temperature}")
chat_engine = index.as_chat_engine(similarity_top_k=TOP_K, chat_mode="best", llm=llm)
return chat_engine
chat_engine = load_index_and_engine(openai_model, temperature, openai_api_key)
Chatbot interface
# === User input ===
if user_input:= st.chat_input("❓ Ask a question:"):
# save user input to chat history
st.session_state.chat_history.append({"role": "user", "content": user_input})
# === Display chat history ===
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.write(message["content"])
# === Generate response if needed ===
if st.session_state.chat_history[-1]["role"] != "scOracle":
with st.chat_message("scOracle"):
with st.spinner("Thinking..."):
response = asyncio.run(chat_engine.achat(user_input))
st.session_state.chat_history.append({"role": "scOracle", "content": str(response)})
st.write(response.response)
scOracle in action